

自分で作ったモデルの精度を上げるには?ノーコードAIプラットフォーム「Learning Center」の使い方

ノーコードAI開発・運用プラットフォーム「Learning Center」は、誰でもすぐにAIモデルを開発することが可能です。今回は、実際に「Learning Center」でモデルを学習させた後、精度を向上のためにどのような点に着目して方針を決めるのが良いのか、新しくリリースした機能の活用方法とも併せてご紹介します。
※内容は記事公開当時のものです
AIを組み込む前に「Learning Center」上で精度をチェック
学習中の表示が、学習完了に変わったら、[モデル] というタブから[トータルロス]を見てみましょう。トータルロスは、正解に対してAIモデルの予測結果がどの程度ずれているかを表す関数をロス(損失関数)を表しています。
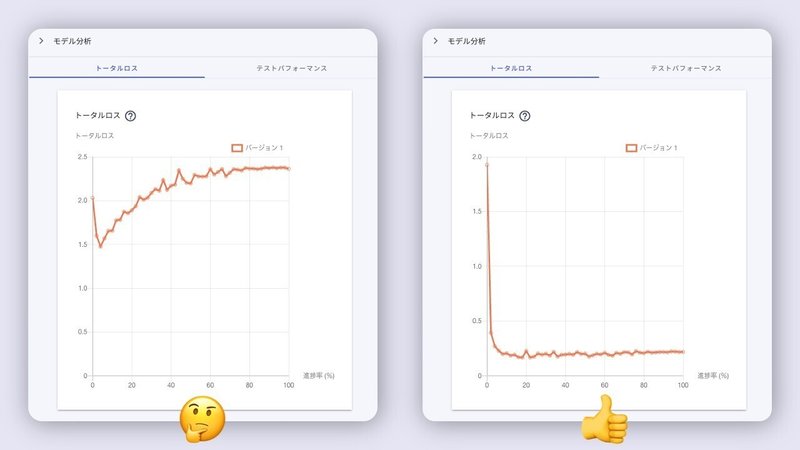
基本的にロスが小さくなっていることで学習が順調なことを確認することができます。つまり、右肩下がりで、数値が低い状態になっていると、ロスの変化自体が小さくなってくることを意味しています。(平均の数値)
ロスが大きくなってしまう要因の一例
・特定の画像データに偏って学習してしまい過学習が起きてしまっている
・学習データ量が足りない
検証用データから課題を見つける
では、「検証データ」を見てみて、AIの予測結果のうち、何がうまくいっていないのか・何がうまくいっているのかを確認しましょう。検証データを開くことで、精度の根拠となっているAIモデルの予測と、アノテーションを行った正解データ(アノテーションデータ)の答え合わせの結果を見ることができます。
※検知したい対象物にラベル付けをした(アノテーションを書いた)もの

学習用データのうち、8割が学習用データとして使われ、残りの2割が検証用データに使われます。「Learning Center」で学習をスタートさせるためには、最低20枚の画像が必要です。推奨しているデータ数は300枚以上です。
「Learning Center」の“精度”は、学習用データを使って学習したAIモデルが出した予測結果を、検証用データを使ってAIモデルがどれぐらい正確に予測できたかを答え合わせすることで算出され、その結果がテストパフォーマンスとして表示されます。検証用データのページは、その答え合わせの内容を確認することができます。
サイドバーから正しく検出しているデータである[正検知データ]をチェックすると、AIが正しく検出している結果がフィルターで表示されます。このビューで、どのラベル(※)が正しく検知できているかをまず見てみましょう。
[誤検出データ]のフィルターをかけると、AIが誤って検出したデータが表示されます。ここで、大まかな間違いの状況を見て、誤検出が起きてしまっている要因に狙いをつけます。
誤検出・検出漏れデータの要因の一部
・アノテーションの枠が小さい・大きい
・学習データ量が不足している
・複数の物体をまとめてひとつの枠でアノテーションしてしまっている
主な対策
・誤検出・検出漏れが多いデータの学習量を増やす(学習用データの追加)
・似ているものや重なっているラベルのアノテーション方法を見直す
・アノテーション数が少ないラベルを増やす
検証用データの結果を見て、精度向上のための方針を決めていきます。例えば、Aの物体は検出できているものの、Bの物体は検出できていない場合、Bのデータを増やすという対策が考えられます。
UXデザイナーからのコメント:
検証用データの結果から講じる対策・傾向の見極めの提案やフィルターの種類については、今後カイゼンしていきたいと考えています!
AIの検知結果が一眼でわかるプレビュー機能をリリース
バージョン 2.5.0 のリリースによって、検証用データの結果だけではなく、実際の推論結果も確認することができるようになりました。API を実装することなく、「Learning Center」上でAIの結果が見えるプレビュー機能が追加されています。
これまで:学習後、API を実装してAIの結果を把握
カイゼン:学習後、API を実装せずにプレビュー機能上に画像をアップロードすることで結果を把握
プレビュー機能によって、AI に検知してもらいたい画像をアップロードするだけで、どこまで検知できているかが見れるようになりました。
運用方法を見ることで、追加学習をすべきかどうか、どのようなデータを学習させるべきかを検討します。
プレビュー機能の使い方
プレビューのタブを開き、[ファイルを選択] から検証したい画像をアップロードします。これは学習用・検証用で使用したデータではなく、全く新しいデータをアップロードすることで、実際の推論結果が確認できます。
モデルのバージョンを選択し、[推論実行] をクリックすると、右側に推論結果が表示されます。
[出力ログ] をクリックすることで、JSON 形式でも確認することができます。

AIを「使う」段階へ
プレビュー機能を活用して、テストした結果、大きく誤検知してしまっている場合は、学習データを見直すことやデータ量を増やしたり、アノテーション(ラベル付)のやり方や再検討したりする方が良いケースがあるため、一つ前のステップの「モデル」の状態を見るように戻りましょう。
推論結果に精度に問題がなければAPI を実装する段階へと進みます。テストパフォーマンスでロスが大きい場合はプレビュー結果が良くても、モデル全体はもう少し改善が必要な場合もあるため、試しながら学習量を増やして精度向上を目指しましょう。
何%の精度を目指せば良いのか
目指しているテストパフォーマンスを最初から100%にするのは難しいことです。業務で活用する場合は、そのモデルを使うことで少しでも作業が効率化できるようにすることや、少し人間のチェックが楽になるというレベルを想定しておく方が良いです。例えば、80%であっても、人が1から目視で確認するより楽になります。
対象のプロセスや業務、状況によって必要なレベルは変わってくるので、まず使いながらデータを貯めていき、より高い精度を目指しましょう。
ヘルプセンター・リリースノートはこちら